
Rock Paper Scissors is Not Solved, In Practice
On prediction, exploitation, and the art of not being exploitable

Rock Paper Scissors is not solved, in practice.
When I was first learning to program in 2016, I spent a few years, off and on, trying to make pretty good Rock Paper Scissors bots. I spent maybe 20 hours on it in total. My best programs won about 60-65% of matches against the field; the top bots were closer to 80%. I never cracked the leaderboard, but I learned something interesting along the way: RPS is a near perfect microcosm of adversarial reasoning. You have two goals in constant tension: predict and exploit your opponent’s moves, and don’t be exploitable yourself. Every strategy is, in essence, a different answer to how you balance those goals.
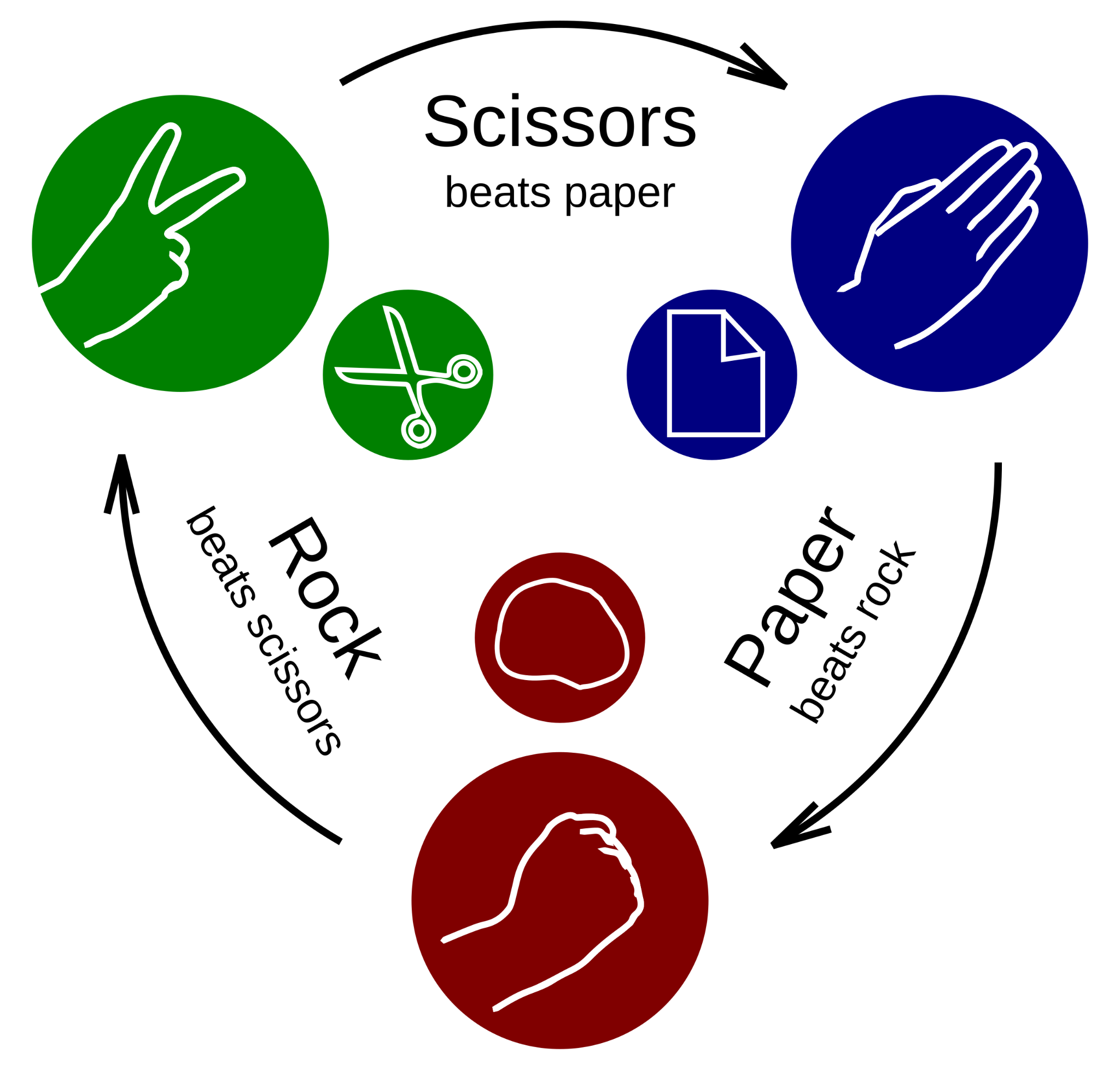
Simple Strategies
Always Rock
The simplest strategy is to play Rock all the time. This is the move that 35% of human players in general, and 50% of male players, open with.
Rock loses to its arch-nemesis, Paper. If you know for sure your opponent will play Rock, you should play Paper. “Always Rock”, then, is a highly exploitable strategy to its natural counter.
On the other hand, if you know for sure your opponent will play Paper, you should play Scissors
This actually happened to me when I first learned about Rock Paper Scissors stats. I saw an earlier version of the chart above, challenged a friend to a game, and he, having seen the same chart, clocked me as a chart reader and played Scissors as a response. Oops.
Of course scissors can be defeated by the original strategy (Rock).
Does that mean there’s no end to the infinite regress? No. There is a simple strategy that can’t be exploited approximately no matter how good your opponent is at reading you.
Pure Random
The best strategy against a superior opponent is to just play purely randomly.
Random play (⅓ chance Rock, ⅓ Paper, ⅓ Scissors) is provably unexploitable. No matter how good your opponent is, as long as they can’t crack the source of your randomness (which is a reliable assumption in computer rock paper scissors), you should expect to win as often as you lose.
Sidebar: Implementation (for humans)
Randomness (or near-perfect pseudorandomness) is easy for bots. Much harder for humans!
Most humans can’t just “play random” by instinct. Instead they need some external source of randomness. Personally, I use digits of pi, which I memorized many digits of (nerd, I know). I then take the digits of pi modulo 3 to form my move1. For example, 0->Rock, 1->Paper, 2->Scissors.
If you want to take rock paper scissors even more seriously than I did, it might behoove you to memorize a longer (and different) string of random numbers/moves.
Why isn’t Pure Random Perfect?
Why isn’t Pure Random just the best strategy? After all, it can’t be exploited at all! This fulfills the technical game theory definition of a Nash Equilibrium: If every player plays the Pure Random strategy, nobody can gain by deviating from it.
Pure Random is an unexploitable strategy that has a 50-50 win-rate against the best strategies. Unfortunately it also has a 50-50 win-rate against the worst strategies.
And some people program bad bots like Always Rock! And you want to exploit those strategies.
Consider Pure Random + Paper Counter, which has two components:
Play Random by default.
If you know for sure your opponent plays Always Rock, play Paper. Otherwise, go to 1.
This strategy is strictly better than both Always Rock and Pure Random. And of course, if you can predict your opponents reasonably well, you can do much better than exploiting a single strategy.
String Finder aka Aaronson Oracle
How do you predict many different idiosyncratic patterns and strategies other people can have? Both humans and bots often repeat patterns, so you can just look for patterns and counter them.
How do you find such patterns? One simple way is to look for past patterns in their play history. For example, if 4 of the last 5 times your opponent played SS, she then plays R afterwards, you can be reasonably sure that if she just played SS, she’s likely to follow with R (so you should counter with P).
Scott Aaronson made a very simple string finder that beats almost all naive human strategies. Check out the Github here, or play against it yourself here (using Collisteru’s implementation).

Sidebar: One-Sided String Finder vs Two-Sided String Finder
For your string finder, you can either record (and use) only your opponent’s past history of moves, or record pairs of moves (both your opponent’s moves and your own).
Both strategies have their place. Recording and pattern-matching on just your opponent’s moves is simpler and reduces the combinatorial space. In contrast, recording pairs of moves is theoretically more complete and represents the full game better (your opponent is trying to predict you, too!)
In practice, most intermediate and advanced bots use both one-sided and two-sided string finders.
Why Aren’t String Finders Perfect?
String-Finders are highly exploitable. If your opponent knows that you’re doing a string finder strategy, they can just invert their history. When they historically played R in a situation, they’ll expect you to play P and will instead play S.
Somebody predicting your string-finder strategy can easily crush you afterwards.
Is it possible to be essentially unexploitable in the limit against smarter strategies while still being able to exploit biases in your opponent’s strategies? Surprisingly, yes.
The “Henny” strategy: Frequency-weighted randomness
The Henny strategy is simple:
Start the first few moves with either random play or another strategy.
Record all your opponent’s past moves.
Then, counter a randomly selected move from your opponent’s entire history
If your opponent has played 30 Rocks, 45 Papers, and 25 Scissors over the last 100 moves, you sample from that distribution and counter it: you’d play Paper 30% of the time, Scissors 45%, and Rock 25% of the time as a reply.
As long as your opponents have any biases at all in their play (e.g., play Paper slightly more than Scissors), you should be able to reliably win against them over the course of many moves.
Further, Henny is not easily exploitable. Firstly, because of the high level of randomness, it’s very hard for your opponents to identify what you’re doing. Secondly, in the limit against unbiased opponents, this strategy just approaches Pure Random, which is Nash Equilibrium.
The Henny strategy is essentially unexploitable in the limit. It also reliably exploits many weak opponents.
Henny’s Main Limitations
The Henny strategy is ultimately a highly-defensive strategy. It’s very hard to exploit by more sophisticated strategies. In turn, it is limited in its ability to exploit other strategies.
First, when it goes against weaker strategies, it usually ekes out a small advantage, and does not fully exploit their weaknesses. This is not a problem for bot competitions, where you win matches over the course of (say) 1000 individual games, and your score at the end of the match is irrelevant. However, it can be a problem in real life human games of best-of-three or best-of-seven, where your small statistical edge might be too small to consistently guarantee a victory.
A bigger problem is that it only exploits a limited slice of predictable strategies. Consider somebody who just plays {RPSRPSRPS…} ad infinitum. This is both in theory and in practice extremely exploitable (the String Finder from earlier can destroy it completely), but from a naive Henny strategy’s perspective, it’s indistinguishable from random!
So a naive Henny strategy, while excelling at being hard to predict and hard to exploit, leaves a lot of money on the table by not being able to exploit any strategy that is not biased by move-frequency.
Can we do better?
The obvious move is to blend the above approaches. You can use frequency-weighting over sequences of moves rather than single moves, or switch between strategies based on how the match is going. But this raises a new question: how do you choose which strategy to use, and when?
This is where the meta-strategies come in.
Meta-Strategy: Iocaine Powder
“They were both poisoned.” - The Masked Man
The most famous meta-strategy for computer Rock Paper Scissors is Iocaine Powder2, named after the iconic scene in Princess Bride, with its endless battle of wits. The basic insight is that any successful prediction (P) for your opponent’s strategy can run at multiple meta-levels.
For example, suppose your predictor says your opponent will play Rock:
Level 0 (P0): Predict what my opponent will play, and counter it. Play Paper.
Level 2 (P1): Counter your opponent’s second guess. Assume your opponent expects you to play the Level 0 strategy. They play Scissors to counter your Paper. So you should play Rock to counter.
Level 4 (P2): Counter your opponent’s fourth guess. Your opponent expects you to play Rock, and plays Paper. So you should play Scissors to counter.
…
At this point, you might expect there to be an infinite regress. Not so! The cyclical nature of RPS means Level 6 (P3) recommends that you play Paper, just like Level 0. So all meta-levels (rotations) of the same predictor reduce down to 3 strategies.
But what if your opponent uses the Predictor P against you and tries to predict your strategy? We have 3 more strategies from the same predictor:
Level -1 (S0): Just play your strategy. Hope your opponent doesn’t figure it out.
Level 1 (S1): Assume your opponent successfully predicted/countered your base strategy. Play 1 level higher than them (2 levels higher than your base strategy).
Level 3 (S2): Left as an exercise to the reader.
So from a single prediction algorithm P, Iocaine Powder introduces 3 rotations and a reflection, giving us 6 distinct strategies. One of them might even be useful! But how do we know which strategies to choose between?
Strategy Selection Heuristics
Suppose you have a pool of strategies: several base predictors, each with 6 Iocaine Powdered variants. How do you choose which one to use at any given moment?
Random Initialization
Rather than play with a prediction right out of the gate, most modern RPS bots will play the first N moves randomly3, and only play moves “for real” when the meta-strategies are reasonably certain of the correct strategy.
History Matching
“Study the past, if you would divine the future” - Confucius, famed algorithmic rock paper scissors enthusiast
The generalization of the String Finder strategy is to apply history matching across not just moves but strategies. Upweight strategies/variants that made correct predictions in the past, and downweight strategies/variants that made bad predictions.
Strategy Switching
To counter history matching meta-strategies, you can try to get ahead of them by switching your strategy consistently. This can either be programmed in hard shifts, or (more commonly in the best bots) organic switches as existing strategies do less well.
Recency Bias
For Iocaine Powder implementations, a common counter to strategy switching is to bias towards strategies that made better recent predictions rather than over the entire history, trying to stay one step ahead of your opponent.
Variable Horizons
Though hard to tune and sometimes too clever, some bots have meta-meta-strategies where the horizon length itself for different meta-strategies are tuned and selected against depending on predictive value.
Database and Evolutionary Attacks
Often, existing strategies (and in most cases, the exact code) of competitor bots are available online. You can thus select the code for the parameters for strategies, meta-strategies, learning rates, etc of your bot ahead of time to be unusually attuned against the existing space of competitor bots, rather than just hypothetical bots in general.
In theory, you can even try to identify the specific bots based on their move patterns and counter hard-coded weaknesses, though this seems difficult and veers into “cheating.”
I haven’t seen this discussed much online before, which is kind of surprising.
Advanced Strategies and Meta-Strategies
Like I said before, I only got to 60-65% on the leaderboards before. But at the time, I wasn’t very good at either programming or board game strategy. What would I try if I want to do better today?
Better Predictors
In the past, I’ve only attempted to implement relatively simple predictors. If I were to try to implement a competitive RPS in 2025, I’d want to experiment with some Markov models and even simple neural nets4, as some of the recent top bots have experimented with.
Improved Meta-Strategy and Strategy Selection
Iocaine Powder in its essential form has been around for at least a decade, maybe longer. I’d be curious whether there are missing meta-strategy and strategic selection alternatives I’ve been sleeping on. So I’d want to think pretty hard and experiment with novel meta-strategies.
In particular I’d be curious to do database/evolutionary search over existing strategies and meta-strategies.
Better Game Design
The core design and strategic objectives of modern RPS bots is relatively simple: 1) predict and exploit your opponent’s moves, and 2) don’t be exploitable yourself. In practice this reduces to a relatively simple set of objectives: 1) make the best predictor possible, which can often be very complex (but not so complex you run past the time limit) 2) “devolve to random” when playing against a more sophisticated strategy that can reliably exploit your own strategy.
Can we add additional constraints, to open the strategic and meta-strategic landscape further?
One thing I’m curious about is RPS with complexity penalty: Same game as before, but you lose fractional points if your algorithm takes more time than the ones you beat. I’d be keen to set up a superior contest, maybe on LessWrong, time and interest permitting. Comment if you’re interested!
Conclusion
In RPS, the twin objectives of predicting your opponent’s moves where being unexploitable yourself mirrors and distills other adversarial board games and video games, and even some zerosum games in Real Life.
If you enjoyed this article, please consider reading my prior article on board game strategy, which I have far greater experience in than RPS bots:
How to Win Board Games

Want to win new board games? There’s exactly one principle you need to learn:
Finally I might run an “RPS bots with complexity penalty” tournament in the near future. Please comment here and/or subscribe to the substack if you’re interested!
Obviously a base 10 rendition of pi has some biases mod 3. Fortunately “0” does not show up in pi until the 32nd digit, long after most people stop playing.
I don’t know the history of the strategy. I think it’s been around for longer than my own interest in the game. This is the best link I can find on the strategy online, but it was not the first time I learned of the strategy, and not the originator.
In the original Iocaine Powder link above, bots would also “resign” if they’re losing and cut their losses by playing randomly. I don’t really see the point with standard scoring rules (which just judges matches between 2 bots as one point for whoever wins the best out of (say) 1000 games. I assume he was writing for an earlier time where the spread of wins minus losses mattered more.
Note however that tournaments often limit running time, so you have to be careful with overly complex strategies.